ByteDance’s OmniHuman is a revolutionary AI, reshaping AI-driven human animation and deepfake technology. Discover how this cutting-edge system generates stunningly realistic human videos from a single image, opening new frontiers in synthetic media while sparking vital ethical conversations. A new era of digital content creation is here, and tools like OmniHuman are leading the charge into a future projected to be a multi-billion dollar market for AI video. Are you ready to explore the possibilities?

Dive deeper into the technology that’s setting new standards for digital human realism and explore how OmniHuman is making advanced animation accessible.
What is OmniHuman? Pioneering the Next Era of AI Animation
The Genesis: OmniHuman-1 by ByteDance
OmniHuman, specifically its initial iteration OmniHuman-1, is a sophisticated AI model developed by ByteDance, the globally recognized tech company behind TikTok. Its unveiling marks a significant inflection point in digital content creation. OmniHuman demonstrates an extraordinary capability to generate ultra-realistic, animated human videos—a form of advanced synthetic media—from minimal input: just one still image and an accompanying audio file. This dramatically lowers the barriers to producing high-quality synthetic media generation and, by extension, potentially sophisticated deepfake content.
Redefining Realism in Synthetic Media and Deepfakes
The core proposition of AI human animation through OmniHuman is transformative. It moves beyond simple facial manipulation to offer full-body animation, nuanced emotional expression, and precise lip synchronization. This technology has the potential to democratize video production, offering powerful new tools for self-expression and content creation previously exclusive to VFX experts, pushing the boundaries of what’s achievable in realistic deepfake creation and synthetic video.
Why is OmniHuman a Significant Leap Forward?
With OmniHuman, creating sophisticated synthetic media, including highly convincing human animations, shifts from a resource-intensive task to a potentially effortless act. This “democratization” has profound implications, potentially redefining user-generated content and positioning ByteDance AI video technology at the forefront of generative AI. The power and accessibility of OmniHuman, particularly its advanced capabilities in generating human-like figures, also spark crucial ethical discussions about its use and its role in advancing deepfake technology, a conversation we are committed to leading responsibly.
Core Capabilities: What Makes OmniHuman a Game-Changer?
From a Single Image to Dynamic Full-Body Animation
OmniHuman-1 distinguishes itself by transforming a single still image and an audio file into a hyperrealistic, animated video. This fundamentally alters input requirements compared to older technologies that often need multiple reference photos or complex 3D models. The model animates the entire human figure, capturing natural-looking gestures, posture, and movement essential for truly believable outputs.
Key Features at a Glance
OmniHuman’s standout performance is built on a suite of advanced features critical for high-fidelity animation and the creation of realistic digital humans:
- Full-Body Animation: Animates the entire figure, not just the face, supporting diverse camera shots and comprehensive depictions.
- Diverse Subject Support: Extends its capabilities beyond humans to animate cartoons, illustrative characters, and even some animals, broadening creative applications.
- Accurate Lip Synchronization & Expressive Speech: Excels in generating lifelike lip movements and facial expressions for both speaking and singing.
- Advanced Emotion Synthesis: Capable of capturing subtle micro-expressions, allowing for a nuanced display of emotions.
- Multi-Aspect Ratio Support: Generates high-fidelity video in various aspect ratios (e.g., 9:16, 1:1, 16:9) without common AI-induced flaws or distortions.
- Realistic Hand Animation & Object Interaction: Proficiently animates hands—a known challenge in AI animation—including interactions with objects.
- Video Driving Capabilities: Supports video input, enabling the animation to mimic actions and styles from a reference video.
- Image Style Adaptability: Works effectively with a wide range of input image qualities and artistic styles.
See OmniHuman Features in Action: View Examples

Expert Insight: “OmniHuman-1 offers substantial improvements over earlier deepfake and AI video generation tools, achieving high-fidelity, full-body animation from just a single image, which is a significant step forward for the field.”
Beyond Human Faces: Versatile Animation Capabilities
A key aspect of OmniHuman’s versatility is its ability to animate non-human subjects. This opens up exciting applications in animated storytelling, gaming development, creating advanced virtual assistants, and more, expanding its utility far beyond human-like digital personas or traditional deepfake applications focused solely on human faces.
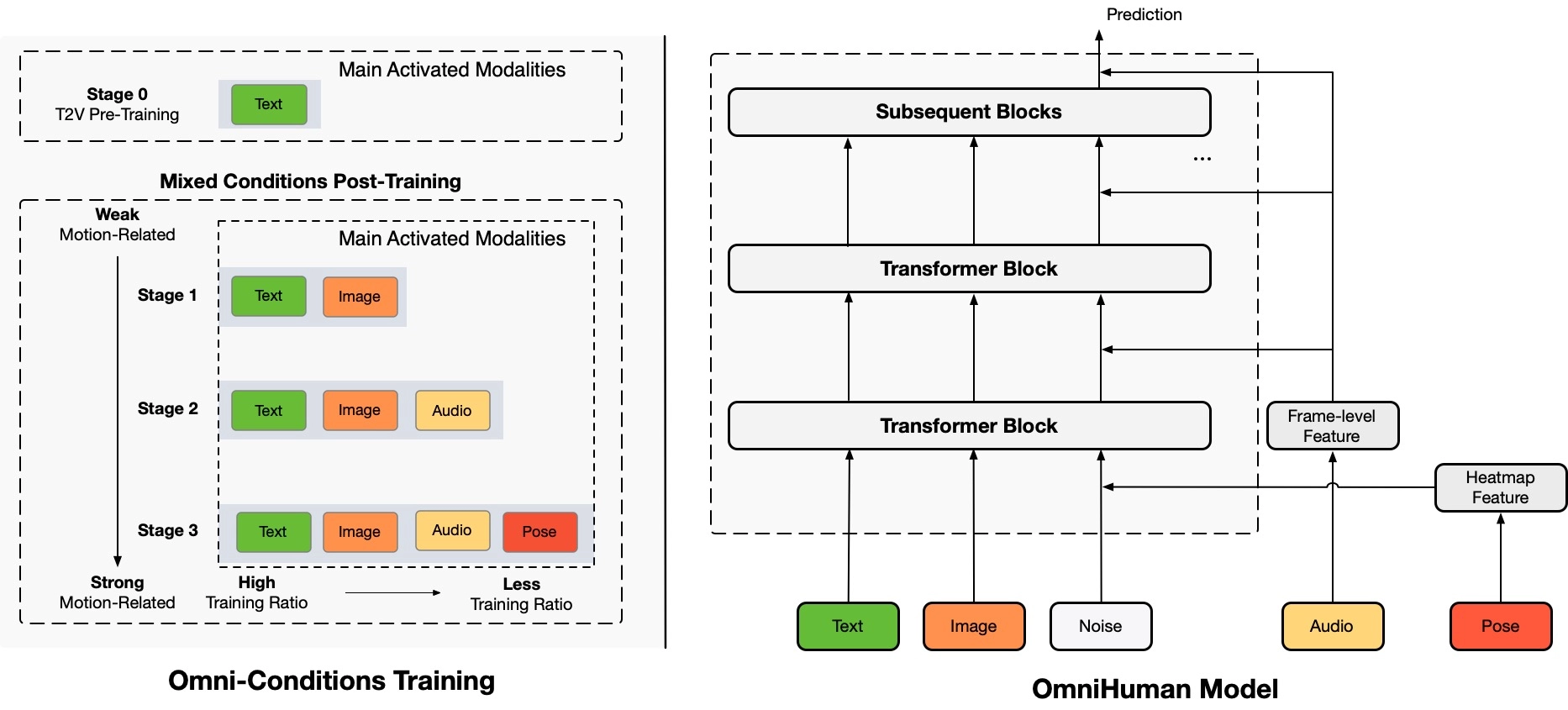
The Technology Powering OmniHuman: DiT and Omni-Conditions
The Engine: Diffusion Transformers (DiT)
OmniHuman‘s groundbreaking capabilities are rooted in a sophisticated Diffusion Transformer (DiT)-based framework. DiT models excel at producing high-fidelity visuals by learning to reverse a noise-addition process. For OmniHuman, a spatiotemporal diffusion model is employed, which meticulously considers spatial details within each frame and temporal consistency across frames. This enables smooth transitions, realistic body dynamics, and the preservation of subject identity—all crucial for convincing AI human animation.
The Method: Innovative “Omni-Conditions” Training Strategy
A cornerstone of OmniHuman’s success is its “omni-conditions training” strategy. This innovative approach involves training the model by concurrently mixing multiple motion-related conditioning signals, such as:
- Text Prompts: Written descriptions that can guide actions and scenarios.
- Audio Inputs: Sound files that drive lip movements, expressions, and even overall animation rhythm.
- Pose Information: Detailed data on body position and movement to ensure anatomical accuracy.
This multifaceted training allows OmniHuman to learn from larger, more varied datasets, significantly reducing data wastage and improving its generalization capabilities for more robust and versatile outputs.
The Result: Enhanced Realism and Versatility Through Training
OmniHuman’s training regimen involves a sophisticated three-stage mixed condition post-training process. It begins with a general text-to-video model which is then progressively adapted and fine-tuned. This layered process, built upon an extensive dataset of over 18,700 hours of diverse human video footage, significantly contributes to the model’s robustness and the fidelity of its output, allowing OmniHuman to achieve superior generalization and a new level of realism in synthetic media.
Transformative Applications: How OmniHuman is Reshaping Industries
OmniHuman‘s applications are poised to catalyze significant transformations across numerous sectors, empowering creativity and innovation.
Revolutionizing Content Creation & Social Media Engagement
OmniHuman empowers a diverse range of users—from individual creators to large organizations—to effortlessly create compelling, AI-driven video content. This is particularly valuable for dynamic platforms like TikTok, potentially leading to an unprecedented surge in engaging synthetic media for creative expression, marketing, and storytelling, while also necessitating a focus on content authenticity.
New Frontiers in Personalized Marketing & Advertising
Marketers can leverage OmniHuman to craft highly personalized and engaging advertisements featuring lifelike AI-generated characters. Brands such as Prada, IKEA, and HPE have already embraced similar AI avatar technology, signaling a growing acceptance and demand for AI personas in commercial communication and customer experience.
Impacting Entertainment, Media, Education, and Beyond
In entertainment, OmniHuman could democratize aspects of film creation, offer new ways to revive historical figures or de-age actors, with profound implications for the media landscape. In education, it offers innovative tools, such as bringing historical figures “back to life” for interactive learning experiences, as demonstrated by AI-generated figures like Albert Einstein. The gaming industry and the burgeoning world of virtual influencers also stand to benefit immensely from this advanced AI animation technology.
OmniHuman’s Performance Edge: A Comparative Look
Benchmarking Against Existing AI Video Generation Models
Research and comparative studies indicate that OmniHuman-1 demonstrates superior performance in key areas of AI video generation. For portrait animation, it reportedly delivers improved realism and motion fluidity compared to established models like SadTalker and Hallo. In the more complex domain of full-body animation, it shows superior performance against models such as CyberHost and DiffTED, setting a new standard for the industry.
Expert Insight: “When benchmarked against several established models in conditioned human animation, OmniHuman-1 has consistently demonstrated superior performance, particularly in achieving natural motion and maintaining identity.”
Key Performance Metrics: Quality, Accuracy, and Fidelity
Evaluations of OmniHuman utilize a range of industry-standard metrics, including Image Quality Assessment (IQA), Aesthetics (ASE), lip-sync accuracy (Sync-C), Fréchet Inception Distance (FID) for image realism, and Fréchet Video Distance (FVD) for video realism. Reports suggest OmniHuman achieves strong, competitive results across these metrics on standard academic datasets, underscoring the high degree of realism and accuracy crucial for believable synthetic personas.
The Double-Edged Sword: Navigating the Ethics of OmniHuman & Deepfake Technology
The emergence of powerful AI like OmniHuman, while technologically impressive, brings with it complex ethical dilemmas that demand careful consideration and proactive management. Its capacity to generate highly realistic human videos from a single image is a “significant leap forward in deepfake technology,” and with great power comes great responsibility.
The Rise of Sophisticated Deepfakes: Potential and Peril
A primary concern is OmniHuman’s potential to fuel the creation of highly sophisticated deepfakes. As noted by AI expert Henry Ajder, advanced generative models can make it “easier than ever to create fake videos for deceptive purposes.” If misused, this could enable widespread misinformation, identity theft, non-consensual synthetic pornography, and political manipulation, especially if the outputs are difficult for current detection tools to identify. The ease of creating such convincing synthetic media is a core ethical challenge that the industry must address collectively.
Privacy, Identity, and Cybersecurity in the Age of AI Avatars
The ability to easily transform personal images into animated videos raises serious privacy and identity theft concerns intrinsically tied to deepfake technology. Potential risks include:
- Identity Theft and Cyber Fraud: Creating convincing fakes for malicious impersonation.
- Reputation Damage and Defamation: Fabricating scenarios or statements to harm individuals or organizations.
- Unethical Content Use: Generating content using someone’s likeness without their informed consent.
These ethical implications of AI avatars and synthetic media demand robust countermeasures, transparent development practices, and clear usage guidelines.
The Imperative for Responsible AI: Development, Detection, and Regulation
OmniHuman underscores the critical need for more robust AI-based deepfake detection tools and clear, adaptable regulatory frameworks. An “arms race” between generation and detection technologies persists. A multi-stakeholder approach involving researchers, developers (like ByteDance), policymakers, ethicists, and the public is essential for fostering responsible AI innovation and mitigating the risks associated with synthetic media. This includes promoting digital literacy and critical thinking skills.
Current Limitations and the Exciting Future of OmniHuman
Despite its impressive capabilities, OmniHuman-1, as an early iteration, has acknowledged limitations. This transparency is key to ongoing refinement and underscores the dynamic nature of AI animation technology.
Acknowledged Technical Constraints & Areas for Growth
Current OmniHuman limitations that the research community and developers may be addressing include:
- Dependency on the quality and clarity of the reference image.
- Challenges with highly complex scenes, extreme poses, or unusual occlusions.
- Significant computational resource demand for training and, potentially, generation.
- Limited initial public availability for broad independent research (though ByteDance’s Dreamina platform offers a related tool, providing some access to the underlying technology).
- Difficulties in perfectly replicating all nuanced human interactions or complex skills, like playing musical instruments with complete fingering accuracy.
Ongoing Research, Planned Enhancements, and the Road Ahead
The development team behind OmniHuman appears to be actively working on refining the model. Public statements and research often indicate a focus on addressing “potential ethical and technical issues,” improving “bias mitigation,” and enhancing real-time performance capabilities. The designation “OmniHuman-1” strongly implies that future, more advanced versions are planned.
This journey with OmniHuman and AI-driven human animation is just beginning. As this technology evolves, it will undoubtedly unlock new creative potentials and efficiencies. However, it also compels us to adapt, fostering digital literacy and critical engagement for a world where the lines between real and synthetic (or “deepfake”) content become increasingly blurred. Responsible innovation is paramount for harnessing OmniHuman‘s benefits while diligently safeguarding against its potential harms.
Frequently Asked Questions (FAQ) about OmniHuman and Deepfake AI
Q: What is OmniHuman?
A: OmniHuman is an advanced AI model developed by ByteDance. It’s a form of deepfake technology designed to generate ultra-realistic, animated human videos from a single image and an audio file, featuring capabilities like full-body animation, emotional expressions, and precise lip-sync.
Q: Who developed OmniHuman-1?
A: OmniHuman-1 was developed by the research teams at ByteDance, the company known for TikTok, showcasing their significant advancements in AI human animation and synthetic media.
Q: What core technology does OmniHuman use?
A: It primarily utilizes a sophisticated Diffusion Transformer (DiT) architecture and an innovative “omni-conditions training” strategy. This approach integrates text, audio, and pose data to achieve highly realistic and controllable synthetic media outputs.
Q: Can OmniHuman animate subjects other than humans?
A: Yes, OmniHuman’s capabilities extend to animating diverse subjects, including cartoon characters, illustrations, and even some animals, making it more versatile than typical deepfake applications focused only on human faces.
Q: What are the main ethical concerns associated with OmniHuman?
A: Key ethical concerns relate to its power as an advanced deepfake tool. These include the potential for misuse in creating misinformation, facilitating identity theft, generating non-consensual content, and for political manipulation, largely due to its realism and the increasing ease of use of such technologies.
Q: How does OmniHuman compare to older deepfake or AI animation tools?
A: OmniHuman generally requires only a single image for full-body animation, which is a significant step up from many older tools that needed multiple images or more complex inputs. It also typically achieves higher realism in motion, expression, and lip synchronization.
Q: Is OmniHuman technology available to the public?
A: While ByteDance has published research on OmniHuman-1, direct public access to the core research model may be limited. However, a related tool leveraging similar technology is available on ByteDance’s creative platform, Dreamina, allowing users to experience some of its capabilities.
Q: How can I learn to use OmniHuman technology?
A: You can explore the capabilities of OmniHuman technology through the AI Avatar tool on the Dreamina platform. Check out our step-by-step tutorial to get started.
Q: Where can I see examples of what OmniHuman can do?
A: We have a dedicated page showcasing various animations created with OmniHuman technology. View OmniHuman examples here.