
OmniHuman-1 is more than another “talking-head” generator—it is a unified framework that turns a single photo into a full-body, hyper-realistic performance driven by audio, pose, or text. This article unpacks OmniHuman-1 technical architecture and training, revealing how its Diffusion Transformer core, multi-stage “omni-conditions” curriculum, and parameter-efficient design set a new benchmark for AI-generated human video.
Why OmniHuman-1 Matters
OmniHuman-1 closes long-standing gaps in synthetic human video—gesture realism, temporal coherence, and style versatility—while slashing input requirements to a lone reference image. Its emergence signals a turning point for content creators, game studios, and immersive-learning platforms seeking photorealistic avatars without motion-capture rigs.
Core Architectural Blueprint
Diffusion Transformer (DiT) Backbone
- Combines step-wise denoising of diffusion with the long-range context handling of Transformers.
- Enables frame-level detail and clip-level coherence simultaneously.
Multimodal Diffusion Transformer (MMDiT)
- Forked from the pretrained “Seaweed” model and extended with cross-modal attention.
- Fuses text, audio, pose, and reference-image tokens in a single sequence for joint reasoning.
Causal 3D Variational Autoencoder
- Compresses video into a latent space, cutting memory cost while retaining motion cues.
- Employs flow-matching to speed convergence and sharpen temporal consistency.
Parameter-Efficient Identity Preservation
- Appearance features from the reference image enter every denoising block via self-attention—no extra identity-specific weights, so model size scales linearly, not per-character.
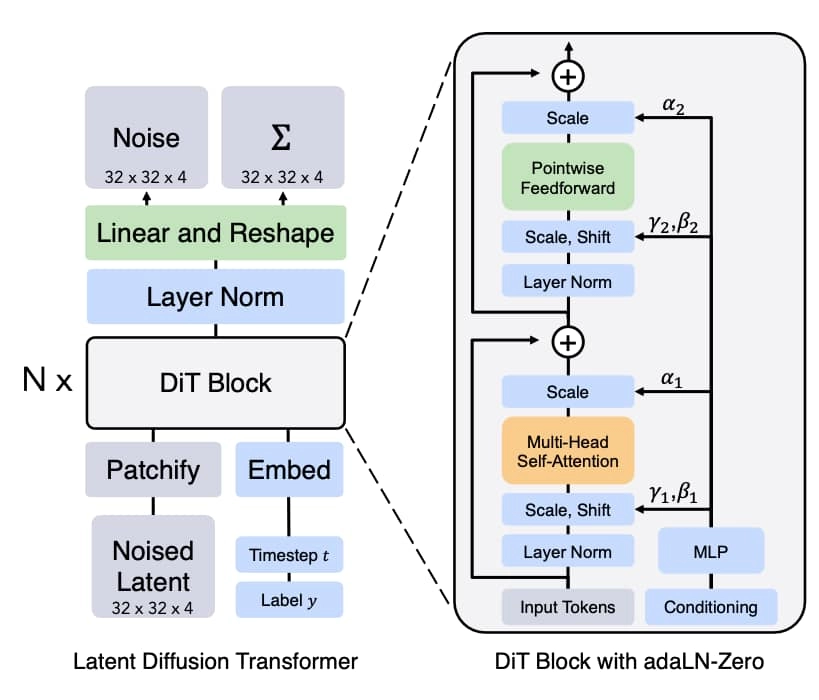
Training Methodology—The Omni-Conditions Curriculum
Stage 1—Text & Image Foundation
The model starts as a general text-to-video generator, absorbing scene semantics and appearance cues.
Stage 2—Audio-Driven Specialization
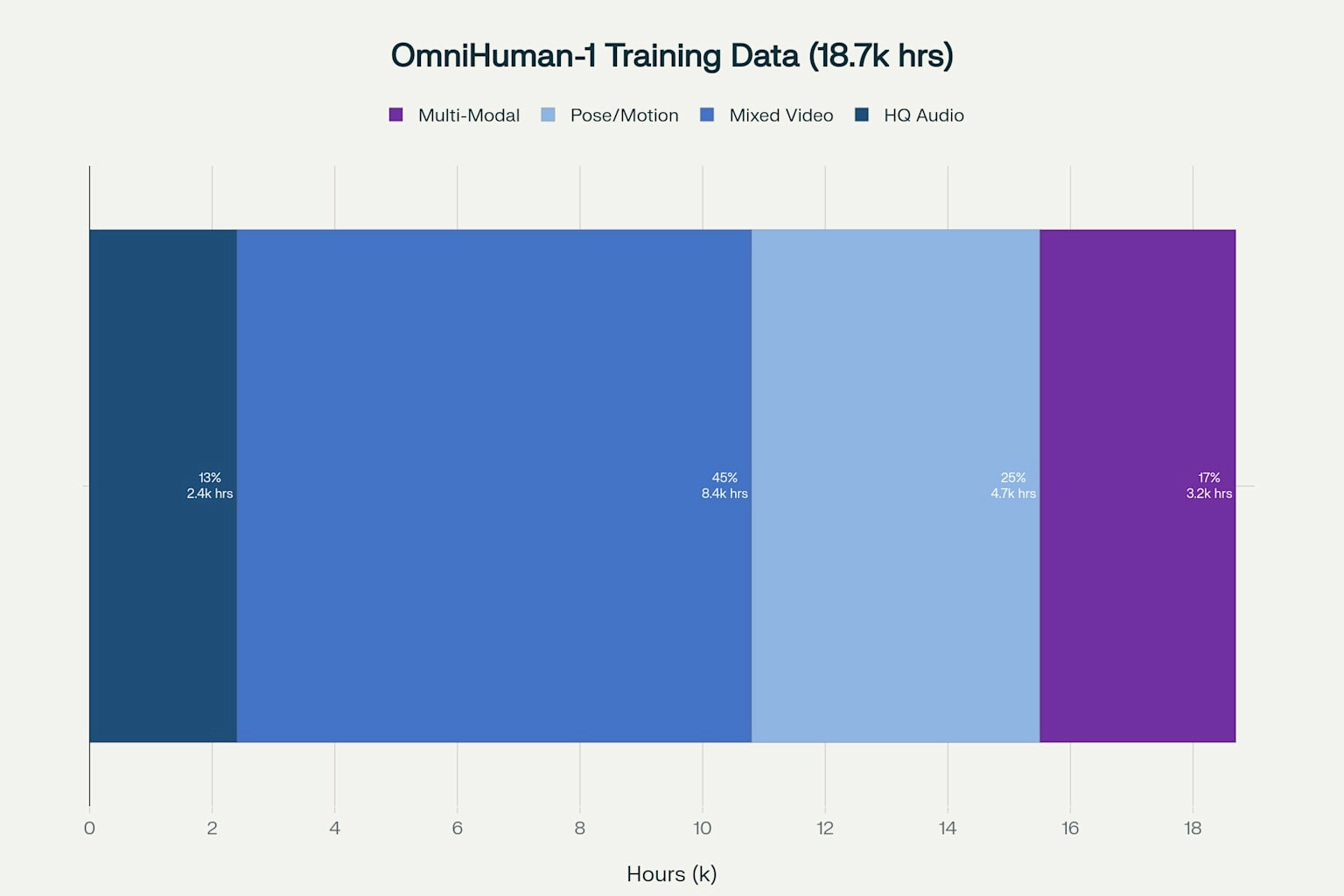
Speech clips (wav2vec features) teach lip-sync and co-speech gestures. Only ~13 % of the 19 k-hour corpus has high-quality audio, yet mixing it with weaker text signals widens data scale.
Stage 3—Pose-Guided Refinement
Dense pose heatmaps add precise kinematics, unlocking dance transfers, complex object interactions, and challenging camera angles.
Data Philosophy—Use Everything, Waste Nothing
Instead of discarding “imperfect” clips, OmniHuman-1 blends weak- and strong-condition samples, trusting the model to learn signal from noise. The payoff is diversity: cartoon styles, anthropomorphic characters, and multiple aspect ratios emerge without extra fine-tuning.
Inference Workflow and Real-Time Optimizations
Conditional Switchboard
During generation the user activates only the needed modalities—audio for talking avatars, pose for dance, combined for music-driven choreography—keeping compute lean.
Segment-Wise Autoregression
Clips longer than GPU memory are produced segment-by-segment; the final five frames of each segment seed the next, preserving motion continuity.
Inference Speed Tricks
- Latent-space diffusion cuts pixel-space overhead.
- Flow-matching and adaptive sampling balance quality vs. FPS.
- Reference-feature reuse avoids repetitive identity encoding passes.
Benchmark Performance & Efficiency
Below is a consolidated snapshot of OmniHuman-1’s standing against leading human-video models.
| Metric | OmniHuman-1 | CyberHost | Loopy | DiffTED | DiffGest | Ideal Direction |
|---|---|---|---|---|---|---|
| Lip-Sync Accuracy | 5.255 | 6.627 | 4.814 | — | — | ↑ Higher |
| Fréchet Video Distance (FVD) | 15.906 | — | 16.134 | 58.871 | — | ↓ Lower |
| Gesture Expressiveness (HKV) | 47.561 | 24.733 | — | — | 23.409 | ↑ Higher |
| Hand Keypoint Confidence (HKC) | 0.898 | 0.884 | — | 0.769 | — | ↑ Higher |
These numbers confirm OmniHuman-1’s edge in overall realism and gesture fidelity, even if a lip-sync-specialist model nips it on that single metric.
Limitations and Future Directions
- Scene Complexity: Background physics and crowded environments still challenge the model.
- Input Quality Sensitivity: Low-resolution or occluded photos degrade output fidelity.
- Compute Demands: High resolutions or 30-second clips require powerful GPUs.
- Micro-Expression Detail: Subtle emotional cues remain an open research frontier.
Future work targets mixed-reality scene synthesis, micro-expression capture, and model-compression techniques such as quantization for mobile deployment.
Putting It All Together—Practical Takeaways
For studios, educators, and developers, OmniHuman-1 delivers:
- Single-Image Simplicity: No volumetric scans or MoCap suits.
- Full-Body Expression: Natural hand gestures and object interactions.
- Multi-Modal Control: Seamless switch between audio, pose, or text drivers.
- Style Agnosticism: From photoreal to cartoon to anthropomorphic.
- Parameter Efficiency: Identity preserved without ballooning weights.
Conclusion & Next Steps
OmniHuman-1 redefines what “end-to-end” means in human animation. By merging a DiT backbone with an omni-conditions curriculum, it scales realism, diversity, and usability all at once. Ready to experiment? Upload a portrait, feed in your audio or dance pose file, and watch a full-body digital double come alive.
FREQUENTLY ASKED QUESTIONS (FAQ)
QUESTION: Can OmniHuman-1 generate videos from text alone?
ANSWER: Yes—thanks to its Seaweed pretraining, it accepts purely textual prompts, but adding a reference image and audio or pose yields far sharper identity retention and motion accuracy.
QUESTION: How long can a single clip be?
ANSWER: Memory limits aside, researchers report stable generation up to 30 seconds by chaining segments, with the last five frames conditioning the next batch for seamless transitions.
QUESTION: What hardware is required for real-time inference?
ANSWER: A high-end GPU (e.g., 24 GB VRAM) handles 512×512 clips around real-time; latent diffusion plus flow-matching keep compute manageable compared to pixel-space models.
QUESTION: Is it possible to edit gestures after generation?
ANSWER: Not yet natively, but exported pose sequences can be edited and re-fed as conditioning data—an interactive control layer is a stated roadmap item.
QUESTION: How does the model avoid identity drift across frames?
ANSWER: Reference-image features are injected via self-attention at every denoising step, so the generator continually “looks back” to the source portrait instead of relying on memory alone.